- Cuando hablamos de bases de datos, en nuestras conversaciones nos referimos a datos relacionales. Esto no fue siempre así, antes que el modelo relacional fuese desarrollado, existió otro modelo de datos.Ahora, el caso para considerar las alternativas ha llegado a ser cada vez más fuerte, con las nuevas generaciones de leguajes de desarrollo orientados a objetos se abre una gama de oportunidades a las aplicaciones, y a su vez a las base de datos con la aparición de las bases de datos nativas, orientadas a guardar estos objetos creados por las aplicacionesPrimera generación: modelo jerárquicos y redEl modelo jerárquicosEl modelo de dato de redSegunda generación de bases de datos.: modelo relacionalAccesando el modelo relacionalModelo relacional con programación de procedimientosModelo relacional con programación orienta a objetosTercera generación: modelo post-relacionalEl modelo de objetoEl modelo objeto a relacional.
- La generación de base de datos, muestra la diversidad de sistemas que se crearon, y los que actualmente existen
- http://www3.uji.es/~mmarques/f47/apun/node6.html
GENERACION DE UN SISTEMA DE BASE DE DATOS
DISEÑO FISICO DE LA BASE DE DATOS
- El diseño de una base de datos se descompone en tres etapas: diseño conceptual, lógico y físico. La etapa del diseño lógico es independiente de los detalles de implementación y dependiente del tipo de SGBD que se vaya a utilizar. La salida de esta etapa es el esquema lógico global y la documentación que lo describe. Todo ello es la entrada para la etapa que viene a continuación, el diseño físico. Uno de los objetivos principales del diseño físico es almacenar los datos de modo eficiente. Para medir la eficiencia hay varios factores que se deben tener en cuenta:
Productividad de transacciones. Es el número de transacciones que se quiere procesar en un intervalo de tiempo.
Tiempo de respuesta. Es el tiempo que tarda en ejecutarse una transacción. Desde el punto de vista del usuario, este tiempo debería ser el mínimo posible.
Espacio en disco. Es la cantidad de espacio en disco que hace falta para los ficheros de la base de datos. Normalmente, el diseñador querrá minimizar este espacio. - la diferencia de estos diseños es que en el diseño conceptual se obtienen requerimientos, en el logico se convierten los requerimientos y en el fisico se realiza construccion de tablas.
- http://www3.uji.es/~mmarques/f47/apun/node94.html
TRANSFORMACION AL MODELO DE BASE DE DATOS
- Reglas de Transformación entre PIM y PSM expresadas en lenguaje natural
De acuerdo con [12], “la descripción de los mappings puede realizarse en lenguaje natural, un algoritmo en un action language o un modelo en un lenguaje de transformación”. En nuestro caso, y como una primera aproximación a las transformaciones de modelos para el desarrollo de BD XML, se ha optado por describir las reglas de transformación en lenguaje natural, para después expresarlas por medio de gramáticas de grafos. Dichas reglas se recogen en la tabla 1. - esto sirve para transformar a manera que tu elijas una base de datos y puede ser en diversos lenguajes.
- http://personales.unican.es/ruizfr/bda/doc/teo/5/bda-t5-diseno-kybele.pdf
ELECCION DE UN SISTEMA GESTOR DE BASE DE DATOS
- Un sistema gestor de bases de datos o SGBD (aunque se suele utilizar más a menudo las
siglas DBMS procedentes del inglés, Data Base Management System) es el software que
permite a los usuarios procesar, describir, administrar y recuperar los datos almacenados
en una base de datos. Si no se dispone de un Sistema Gestor de Base de Datos o que se encuentre obsoleto se debe escoger un SGBD que sea adecuado para el sistema de información esta elecciòn se debe hacer en cualquier momento antes del diseño lògico. - este sistema permite a lo usuarios procesar y recuperar los datos almacenados en una base de datos.
- http://www.monografias.com/trabajos34/base-de-datos/base-de-datos.shtml#diseno
DISEÑO CONCEPTUAL DE LA BASE DE DATOS
- El éxito del DBMS reside en mantener la seguridad e integridad de los datos. Lógicamente
tiene que proporcionar herramientas a los distintos usuarios. Entre las herramientas que
proporciona están:
Herramientas para la creación y especificación de los datos. Así como la estructura
de la base de datos.
Herramientas para administrar y crear la estructura física requerida en las unidades
de almacenamiento.
Herramientas para la manipulación de los datos de las bases de datos, para añadir,
modificar, suprimir o consultar datos.
Herramientas de recuperación en caso de desastre
Herramientas para la creación de copias de seguridad
Herramientas para la gestión de la comunicación de la base de datos - mantiene seguridad de los datos y proporciona a los usuariosherramientas .
- http://www.jorgesanchez.net/bd/disenoBD.pdf
RECOLLECION Y ANALISIS DE INFORMACION
- LA RECOLECCIÓN DE DATOS La actual generación en constante lucha por la verdad se ha valido de rigurosos cuestionamientos, que han trazado el legado en la humanidad. El comprender la información de una manera objetiva marcado por una unidad compuesta llamada grupo ha logrado el desarrollo de los sistemas de información esa necesidad de conocimiento ha permitido a la ciencia de la comunicación crear rutinas de aprendizaje que se aproximan cada vez más a predecir sucesos de unanimidad; ahora el hombre no solo se limita a saber si no también como puede aplicar lo que sabe.
- son tecnicas para el analisis y desarrollo en los sistemas de informacion que permiten asistir a los fenomenos y extraer informacion.
- http://www.monografias.com/trabajos12/recoldat/recoldat.shtml
CICLO DE VIDA DEL SISTEMA DE APLICACION DE BASE DE DATOS
- Las etapas del ciclo de vida de una aplicación de bases de datos son las siguientes:
Planificación del proyecto.
Definición del sistema.
Recolección y análisis de los requisitos.
Diseño de la base de datos.
Selección del SGBD.
Diseño de la aplicación.
Prototipado.
Implementación.
Conversión y carga de datos.
Prueba.
Mantenimiento.
Estas etapas no son estrictamente secuenciales. De hecho hay que repetir algunas de las etapas varias veces, haciendo lo que se conocen como ciclos de realimentación. Por ejemplo, los problemas que se encuentran en la etapa del diseño de la base de datos pueden requerir una recolección de requisitos adicional y su posterior análisis. - este ciclo contiene 11 pasos que sirven para planificar de una manera mas eficiente las etapas del ciclo de la vida y los limites de aplicacion en una base de datos.
- http://www3.uji.es/~mmarques/f47/apun/node67.html
MODELO 3 NIVELES
- El objetivo de la arquitectura de tres niveles es el de separar los programas de aplicación de la base de datos física. En esta arquitectura, el esquema de una base de datos se define en tres niveles de abstracción distintos:
En el nivel interno se describe la estructura física de la base de datos mediante un esquema interno. Este esquema se especifica mediante un modelo físico y describe todos los detalles para el almacenamiento de la base de datos, así como los métodos de acceso.
En el nivel conceptual se describe la estructura de toda la base de datos para una comunidad de usuarios (todos los de una empresa u organización), mediante un esquema conceptual. Este esquema oculta los detalles de las estructuras de almacenamiento y se concentra en describir entidades, atributos, relaciones, operaciones de los usuarios y restricciones. En este nivel se puede utilizar un modelo conceptual o un modelo lógico para especificar el esquema.
En el nivel externo se describen varios esquemas externos o vistas de usuario. Cada esquema externo describe la parte de la base de datos que interesa a un grupo de usuarios determinado y oculta a ese grupo el resto de la base de datos. En este nivel se puede utilizar un modelo conceptual o un modelo lógico para especificar los esquemas. - se emplean para separar programas de aplicacion de base de datos fisicas y se divide en tres niveles y son el interno, externo
- http://www.monografias.com/trabajos37/arquitectura-de-sistemas/arquitectura-de-sistemas.shtml
OPERADORES PRIMITIVOS, DERIVADOS Y ADICIONALES DE CONSULTA
- Operadores primitivos: Los operadores primitivos son parte del modelo relacional y pueden realizar diferentes acciones como Unión, Diferencia, etc.
Operadores derivados: Los operadores derivados son aquellos que se pueden expresar siempre en función de operadores primitivos, pero su introducción tiene por fin la simplificación de las consultas.
Los operadores derivados son aquellos que se obtienen de otros en este caso podrian ser los primitivos
Operadores adicionales: Los operadores permiten realizar operaciones aritméticas, comparaciones, concatenaciones o asignaciones de valores. Por ejemplo, puede probar datos para comprobar que la columna de país o región de los datos de clientes está llena o no es NULL
En las consultas, cualquier persona que pueda ver los datos de la tabla que se deben usar con algún tipo de operador puede realizar operaciones. Para poder cambiar los datos correctamente, debe disponer de los permisos adecuados.
Permite cambiar datos, permanente o temporalmente.Los operadores primitivos son los que realizan acciones de unión.Los derivados son los que dependen de otro por ejemplo de los primitivos.Los adicionales son los que nos ayudan a hacer acciones aritmeticas etc.
los primitivos son los que pueden realizar uniones, los derivados se pueden expresar en operaciones de primitivos, los adicionales permiten realizar operacion aritmeticas
TERCER FORMA NORMAL
- La tercera forma normal (3NF) es una forma normal usada en la normalización de bases de datos. La 3NF fue definida originalmente por E.F. Codd[1] en 1971. La definición de Codd indica que una tabla está en 3NF si y solo si las dos condiciones siguientes se mantienen:
La tabla está en la segunda forma normal (2NF)
Ningún atributo no-primario de la tabla es dependiente transitivamente de una clave candidata
Un atributo no-primario es un atributo que no pertenece a ninguna clave candidata. Una dependencia transitiva es una dependencia funcional X → Z en la cual Z no es inmediatamente dependiente de X, pero sí de un tercer conjunto de atributos Y, que a su vez depende de X. Es decir, X → Z por virtud de X → Y e Y → Z.
tambien es usada en la normalizacion de base de datos para poder trabajar con esta forma es necesario tener en una tabla las segunda forma
SEGUNDA FORMA NOrmal
- La segunda forma normal (2NF) es una forma normal usada en normalización de bases de datos. La 2NF fue definida originalmente por E.F. Codd[1] en 1971. Una tabla que está en la primera forma normal (1NF) debe satisfacer criterios adicionales para calificar para la segunda forma normal. Específicamente: una tabla 1NF está en 2NF si y solo si, dada cualquier clave candidata y cualquier atributo que no sea un constituyente de la clave candidata, el atributo no clave depende de toda la clave candidata en vez de solo una parte de ella.
En términos levemente más formales: una tabla 1NF está en 2NF si y solo si ninguno de sus atributos no-principales son funcionalmente dependientes en una parte (subconjunto propio) de una clave candidata. (Un atributo no-principal es uno que no pertenece a ninguna clave candidata).
Observe que cuando una tabla 1NF no tiene ninguna clave candidata compuesta (claves candidatas consistiendo en más de un atributo), la tabla está automáticamente en 2NF
al igual que la primer forma esta se usa en la normalizacion de base de datos pero tiene que satisfacer muchos mas criterios
PRIMER FORMAL NORMAL
- La primera forma normal (1FN o forma mínima) es una forma normal usada en normalización de bases de datos. Una tabla de base de datos relacional que se adhiere a la 1FN es una que satisface cierto conjunto mínimo de criterios. Estos criterios se refieren básicamente a asegurarse que la tabla es una representación fiel de una relación y está libre de "grupos repetitivos".
Sin embargo, el concepto de "grupo repetitivo", es entendido de diversas maneras por diferentes teóricos. Como consecuencia, no hay un acuerdo universal en cuanto a qué características descalificarían a una tabla de estar en 1FN. Muy notablemente, la 1FN, tal y como es definida por algunos autores excluye "atributos relación-valor" (tablas dentro de tablas) siguiendo el precedente establecido por E.F. Codd) (algunos de esos autores son: Ramez Elmasri y Shamkant B. Navathe). Por otro lado, según lo definido por otros autores, la 1FN sí los permite (por ejemplo como la define Chris Date).
forma normal que se usa en la normalizacion de base de datos y es la que satisface diversos tipos de criterios
http:/es.wikipedia.org/wiki/primera
NORMALIZACION DE BASE DE DATOS
- el proceso de normalizacion de bases de datos consiste en aplicar una serie de reglas a las relaciones obtenidas tras el paso del modelo entidad-relacion al modelo relacional. las bases de datos relacionales se normalizan para:
- evitar la redundancia de los datos
- evitar problemas de actualizacion de los datos en las tablas.
- proteger la integridad de los datos
- es aplicar reglas a otras relaciones que son obtenidas utilizando dos modelos el de entidad-relacion y relacional.
- http://es.wikipedia.org/wiki/normalizacion
REQUERIMIENTOS DE LA CONSTRUCCION
- HARDWARE
Se requiere de un servidor para el almacenamiento y manejo de la base de datos corporativa; este servidor se recomienda que sea altamente escalable, pues algunas veces el proyecto de construcción de la bodega presenta redimensionamiento a medida que se avanza en la implementación. La capacidad inicial de almacenamiento estará determinada por los requerimientos de información histórica presentados por la empresa y por la perspectiva de crecimiento que se tenga.
Dependiendo del diseño del sistema, puede ser necesario contar con un segundo servidor para las herramientas de consulta de datos. Este equipo debe tener el sistema operativo recomendado por el proveedor de la herramienta a utilizar, siendo el más usado alguna versión de Windows.
Las estaciones de trabajo de cada usuario deberán cumplir con las características recomendadas por el proveedor de la herramienta de consulta seleccionada.
HERRAMIENTAS DE SOFTWARE
Las herramientas se clasifican en cuatro categorías básicas: Herramientas de Almacenamiento (bases de datos, bases de datos multidimensionales), Herramientas de Extracción y Colección, Herramientas para Reportes de Usuario Final y Herramientas para Análisis Inteligentes.
Herramientas de Almacenamiento: corresponde a la herramienta en la cual se irán a almacenar los datos. Existen muchas opciones, dependiendo del volumen de los datos, presupuesto, y capacidad de su sistema. Cada uno de los sistemas de administración de bases de datos, como Oracle, DB2, Informix, TeraData, Sybase, etc, tienen una facilidad de Data Warehouse.
Herramientas de Extracción y Colección: Ayudan a definir, acumular, totalizar y filtrar los datos de sus sistemas transaccionales en el Data Warehouse. La mayoría de esas herramientas son desarrolladas por el personal interno de la compañía dado el gran conocimiento que tienen de los sistemas transaccionales.
Herramientas para Elaboración de Reportes a Usuarios Finales: Es la interface vista por el usuario. Al usuario se le debe proveer un mecanismo para que vea los datos a un alto nivel y que entonces obtenga con ello la solución a preguntas específicas. Existen muchas herramientas, incluyendo Cognos Powerplay, Business Objects, SAS, ShowCase Strategy, etc.
Herramientas de Análisis Inteligente: Entre ellas están las de empresas como IBM, SAS, Arbor, Cognos, Business Objects, entre otras. Estas herramientas han sido construidas utilizando inteligencia artificial, buscan alrededor del Data Warehouse modelos y relaciones en los datos. Estas herramientas utilizan una técnica conocida como Data Minning o Minería de datos. - para construir base de datos se necesita de capacidades para manejar la computadora y de softweres
- http://planeacion.udea.edu.co/datamart/requerimientos.htm
MODELO ANSI SPARK
- En 1975, el comité ANSI-SPARC (American National Standard Institute - Standards Planning and Requirements Committee) propuso una arquitectura de tres niveles para los sistemas de bases de datos, que resulta muy útil a la hora de conseguir estas tres características.
El objetivo de la arquitectura de tres niveles es el de separar los programas de aplicación de la base de datos física. En esta arquitectura, el esquema de una base de datos se define en tres niveles de abstracción distintos:
En el nivel interno se describe la estructura física de la base de datos mediante un esquema interno. Este esquema se especifica mediante un modelo físico y describe todos los detalles para el almacenamiento de la base de datos, así como los métodos de acceso.
En el nivel conceptual se describe la estructura de toda la base de datos para una comunidad de usuarios (todos los de una empresa u organización), mediante un esquema conceptual. Este esquema oculta los detalles de las estructuras de almacenamiento y se concentra en describir entidades, atributos, relaciones, operaciones de los usuarios y restricciones. En este nivel se puede utilizar un modelo conceptual o un modelo lógico para especificar el esquema.
En el nivel externo se describen varios esquemas externos o vistas de usuario. Cada esquema externo describe la parte de la base de datos que interesa a un grupo de usuarios determinado y oculta a ese grupo el resto de la base de datos. En este nivel se puede utilizar un modelo conceptual o un modelo lógico para especificar los esquemas. - es el modelo que separa los programas de aplicacion de base datos se especifica mediante un metodo logico
http://www3.uji.es/~mmarques/f47/apun/node33.html
MODELO RELACIONAL
El modelo relacional fue presentado por la E. F. Codd en 1970 [2] como un modo de hacer sistemas de gestión de datos más independientes de cualquier uso particular. Esto es un modelo matemático definido en términos de predicado lógico y la teoría de juego.
Los productos que son bases de datos relacionales generalmente llamadas de hecho ponen en práctica un modelo que es sólo una aproximación al modelo matemático definido por Codd. Tres términos clave son usados extensivamente en el Modelo Relacional: relaciones, atributos, y dominios. Una relación, figurativamente hablando, es una tabla con columnas y filas. El atributo, es un descriptor de la relacion, figurativamente hablando, sería el encabezado de cada una de las columnas de la tabla. El dominio de un atributo es el conjunto de valores legales que puede tomar el artibuto.
La estructura de datos básica del modelo relacional es la tabla, donde la información sobre una entidad particular (decir, un empleado) es representado en columnas y filas (también llamado tuples). Así, "la relación" en "la base de datos relacionada" se refiere a varias tablas en la base de datos; una relación es un juego de tuples. Las columnas enumeran varios atributos de la entidad (el nombre del empleado, la dirección o el número de teléfono, por ejemplo), y una fila es un caso real de la entidad (un empleado específico) que es representado por la relación. Por consiguiente, cada tuple de la tabla de empleado representa varios atributos de un empleado solo.
la informacion en este modelo es representada en columnas y filas y la relacion se refiere entre varias tablas dentro de la base de datos.
http://es.wikipedia.org/wiki/Modelo_de_base_de_datos
MODELO ENTIDAD DE RELACION
El Modelo Entidad-Relación, también conocido como DER (diagramas entidad-relación) es una herramienta de modelado para bases de datos, propuesto por Peter Chen en 1976, mediante el cual se pretende 'visualizar' los objetos que pertenecen a la Base de Datos como entidades (se corresponde al concepto de clase, cada tupla representaría un objeto, de la Programación Orientada a Objetos) las cuales tienen unos atributos y se vinculan mediante relaciones.
Es una representación conceptual de la información. Mediante una serie de procedimientos se puede pasar del modelo E-R a otros, como por ejemplo el modelo relacional.
El modelado entidad-relación es una técnica para el modelado de datos utilizando diagramas entidad relación
es en el que la informacion se representa de forma conceptual y se utiliza una tecnica para modelar los datos atraves de diagramas.
http://es.wikipedia.org/wiki/Modelo_de_base_de_datos
MODELO JERARQUICO
En un modelo jerárquico, los datos son organizados en una estructura parecida a un árbol, implicando un eslabón solo ascendente en cada registro para describir anidar, y un campo de clase para guardar los registros en un orden particular en cada lista de mismo-nivel. Las estructuras jerárquicas fueron usadas extensamente en los primeros sistemas de gestión de datos de unidad central, como el Sistema de Dirección de Información (IMS) por la IBM, y ahora describen la estructura de documentos XML. Esta estructura permite un 1:N en una relación entre dos tipos de datos. Esta estructura es muy eficiente para describir muchas relaciones en el verdadero real; recetas, índice, ordenamiento de párrafos/versos, alguno anidó y clasificó la información. Sin embargo, la estructura jerárquica es ineficaz para ciertas operaciones de base de datos cuando un camino lleno (a diferencia del eslabón ascendente y el campo de clase) también no es incluido para cada registro.
este modelo es muy eficiente para describir cosas y clasificar informacion de forma ordenada y estructurada
http://es.wikipedia.org/wiki/Modelo_de_base_de_datos
MODELO DE RED
El modelo de red (definido por la especificación CODASYL) organiza datos que usan dos fundamental construcciones, registros llamados y conjuntos. Los registros contienen campos (que puede ser organizado jerárquicamente, como en el lenguaje COBOL de lenguaje de programación). Los conjuntos (para no ser confundido con conjuntos matemáticos) definen de uno a varios relaciones entre registros: un propietario, muchos miembros. Un registro puede ser un propietario en cualquier número de conjuntos, y un miembro en cualquier número de conjuntos.
El modelo de red es una variación sobre el modelo jerárquico, al grado que es construido sobre el concepto de múltiples ramas(estructuras de nivel inferior) emanando de uno o varios nodos (estructuras de nivel alto), mientras el modelo se diferencia del modelo jerárquico en esto las ramas pueden estar unidas a múltiples nodos. El modelo de red es capaz de representar la redundancia en datos de una manera más eficiente que en el modelo jerárquico.
Las operaciones del modelo de red son de navegación en el estilo: un programa mantiene una posición corriente, y navega de un registro al otro por siguiente las relaciones en las cuales el registro participa. Los registros también pueden ser localizados por suministrando valores claves.
Aunque esto no sea un rasgo esencial del modelo, las bases de datos de red generalmente ponen en práctica las relaciones de juego mediante indicadores que directamente dirigen la ubicación de un registro sobre el disco. Esto da el funcionamiento de recuperación excelente, a cargo de operaciones como la carga de base de datos y la reorganización.
La mayor parte de bases de datos de objeto usan el concepto de navegación para proporcionar la navegación rápida a través de las redes de objetos, generalmente usando identificadores de objeto como indicadores "inteligentes" de objetos relacionados. Objectivity/DB, por ejemplo, los instrumentos llamados 1:1, 1:muchos, muchos:1 y muchos:muchos, llamados relaciones que pueden cruzar bases de datos. Muchas bases de datos de objeto también apoyan SQL, combinando las fuerzas de ambos modelos.
es el modelo que contiene datos que presentan una redundancia y son muy eficaces.
http://es.wikipedia.org/wiki/Modelo_de_base_de_datos
MODELOS DE BASE DE DATOS
Un modelo de base de datos o esquema de base de datos es la estructura o el formato de una base de datos, descrita en un lenguaje formal soportada por el sistema de gestión de bases de datos. En otras palabras, un "modelo de base de datos" es la aplicación de un modelo de datos usado en conjunción con un sistema de gestión de bases de datos.
Los esquemas generalmente son almacenados en un diccionario de datos. Aunque un esquema se defina en un lenguaje de base de datos de texto, el término a menudo es usado para referirse a una representación gráfica de la estructura de la base de datos.
un modelo de base de datos es la forma que se le da a una base de datos, que se usa en conjunto con los sistemas de gestion de base de datos.
http://es.wikipedia.org/wiki/Modelo_de_base_de_datos
TIPO DE GESTORES DE BASE DE DATOS
- son un tipo de software muy específico, dedicado a servir de interfaz entre la base de datos, el usuario y las aplicaciones que las utilizan.
Existen distintos objetivos que deben cumplir los SGBD:
- Abstracción de la información. Los SGBD ahorran a los usuarios detalles acerca del almacenamiento físico de los datos. Da lo mismo si una base de datos ocupa uno o cientos de archivos, este hecho se hace transparente al usuario. Así, se definen varios niveles de abstracción.
- Independencia. La independencia de los datos consiste en la capacidad de modificar el esquema (físico o lógico) de una base de datos sin tener que realizar cambios en las aplicaciones que se sirven de ella.
- Consistencia. En aquellos casos en los que no se ha logrado eliminar la redundancia, será necesario vigilar que aquella información que aparece repetida se actualice de forma coherente, es decir, que todos los datos repetidos se actualicen de forma simultánea. Por otra parte, la base de datos representa una realidad determinada que tiene determinadas condiciones, por ejemplo que los menores de edad no pueden tener licencia de conducir. El sistema no debería aceptar datos de un conductor menor de edad. En los SGBD existen herramientas que facilitan la programación de este tipo de condiciones.
- Seguridad. La información almacenada en una base de datos puede llegar a tener un gran valor. Los SGBD deben garantizar que esta información se encuentra segura de permisos a usuarios y grupos de usuarios, que permiten otorgar diversas categorías de permisos.
- Manejo de transacciones. Una
- Tiempo de respuesta. Lógicamente, es deseable minimizar el tiempo que el SGBD tarda en darnos la información solicitada y en almacenar los cambios realizados.
INFORMES Y REPORTES
Un informe access no es mas que una tabla o consulta mostrada en una forma "elegante y dinámica", los informes son uno de los módulos de access mas importantes, ya que permiten automatizar en gran medida el desarrollo de documentos a partir de bases de datos. Gracias a las herramientas de agrupación y ordenación de datos, y combinado con el código vba que podemos asociar al informe.
son tablas que se muestran o presentan con una vista diferente y dinamica a lo que normalmente se conoce como una tabla
httpp://www.programarvba.com/informes
consultas y formularios
- CONSULTAS Y FORMULARIOS
- Una consulta de comandos aporta modificaciones a muchos registros con una única operación. Existen cuatro tipos de consultas de comando: de Eliminación, de Actualización, de Alineación y de Creación de Tablas.
-Consultas de eliminación: este tipo de consulta elimina un grupo de registros de una o más tablas. Existe la posibilidad, por ejemplo, de utilizar una consulta de eliminación para reemplazar los productos que se han dejado de producir o para aquellos sobre los cuales no existen pedidos. Con las consultas de eliminación siempre se eliminan registros internos y no únicamente determinados campos de su interior.
-Consultas de actualización: este tipo aporta modificaciones globales a uno o más tablas. Existe la posibilidad, por ejemplo, de aumentar en un 10 por ciento el precio de todos los productos lácteos o aumentar los salarios en un 5 por ciento a las personas pertenecientes a una determinada categoría laboral.
-Consultas de alineación: estas consultas agregan un grupo de registros de una o más tablas al final de una o más tablas. Supongamos, por ejemplo, que se han conseguido nuevos clientes y existe una base de datos que contiene una tabla de información sobre estos. En vez de teclear nuevamente todas estas informaciones, se alinean en la tabla correspondiente de Clientes.
-Consultas de creación de tablas: este tipo de consultas crea una nueva tabla basándose en todos los datos o parte de estos existentes en una o más tablas.
-Consultas de parámetros: una consulta de parámetros es una consulta que, cuando se ejecuta, muestra una ventana de diálogo que solicita informaciones, como por ejemplo criterios para recuperar registros o un valor que se desea insertar en un campo.
La programación de formularios con Microsoft Access resulta rápida e intuitiva, aunque previamente es necesario conocer los diferentes controles y eventos que se utilizan. Un Formulario esta compuesto por controles, ya sean cajas de texto, botones, gráficos e incluso archivos multimedia, mientras que los eventos son las acciones que se desencadenan al actuar sobre dichos controles. Estas acciones van desde un simple click hasta pasar por encima del ratón, doble click, etc...
- una consulta nos sirve para buscar y recuperar datos y nos sirve tambien para borrar y actualizar varios datos al mismo tiempo y un formulario nos sirve para ver escribir y cambior de manera sencilla datos de una tabla.
http://www.programarvba.com/formularios-access.htm
http://www.duiops.net/manuales/access/access10.htm
TABLA, CLAVE Y RELACIONES
- TABLA, CLAVE Y RELACIONES
Una tabla es una colección de datos sobre un tema específico, como productos o proveedores. Al usar una tabla independiente para cada tema, los datos se almacenan sólo una vez. Esto tiene como resultado una base de datos más eficaz y menos errores de entrada de datos.
Las tablas organizan datos en columnas (denominadas campos) y filas (denominadas registros).
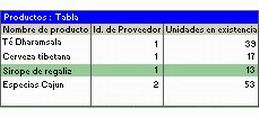
Por ejemplo, cada campo de una tabla Productos contiene el mismo tipo de información para cada producto, por ejemplo, su nombre. Cada uno de los registros de esa tabla contiene toda la información acerca de un producto, por ejemplo, el nombre del producto, el Id. de proveedor, las unidades en existencia, etc.
Una vez creadas tablas diferentes para cada tema de la base de datos de Microsoft Access (base de datos de Microsoft Access: colección de datos y objetos (como tablas, consultas o formularios), que está relacionada con un tema o propósito concreto. El motor de base de datos Microsoft Jet administra los datos.), necesita una forma de indicarte a Microsoft Access cómo debe volver a combinar esa información. El primer paso de este proceso es definir relaciones (relación: asociación que se establece entre campos comunes (columnas) en dos tablas. Una relación puede ser uno a uno, uno a varios o varios a varios.) entre las tablas.
Una vez realizada esta operación, puede crear consultas, formularios e informes para mostrar información de varias tablas a la vez. Por ejemplo, este formulario incluye información de cuatro tablas:
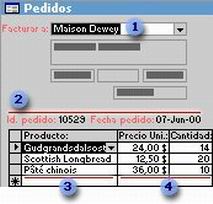
La tabla Clientes
La tabla Pedidos
La tabla Productos
La tabla Detalles de pedidos
Siguiendo en el ejemplo anterior, los campos de las cuatro tablas deben coordinarse de modo que muestren información acerca del mismo pedido. Esta coordinación se lleva a cabo mediante las relaciones entre las tablas. Una relación hace coincidir los datos de los campos clave (normalmente un campo con el mismo nombre en ambas tablas). En la mayoría de los casos, estos campos coincidentes son la clave principal (clave principal: uno o más campos (columnas) cuyos valores identifican de manera exclusiva cada registro de una tabla. Una clave principal no puede permitir valores Nulo y debe tener siempre un índice exclusivo. Una clave principal se utiliza para relacionar una tabla con claves externas de otras tablas.) de una tabla, que proporciona un identificador único para cada registro, y una clave externa (clave externa: uno o más campos de tabla (columnas) que hacen referencia al campo o campos de clave principal de otra tabla. Una clave externa indica cómo están relacionadas las tablas.) de la otra tabla. Por ejemplo, los empleados pueden asociarse a los pedidos de los que son responsables mediante la creación de una relación entre los campos Id. de empleado.
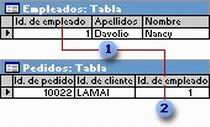
Id. de empleado aparece en ambas tablas, como clave principal ... y como clave externa.
Una relación uno a varios
La relación uno a varios es el tipo de relación más común. En este tipo de relación, un registro de la Tabla A puede tener muchos registros coincidentes en la Tabla B, pero un registro de la Tabla B sólo tiene un registro coincidente en la Tabla A.
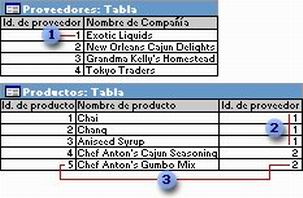
Un proveedor ...
puede suministrar más de un producto
pero cada producto tiene un único proveedor.
En una relación varios a varios, un registro de la Tabla A puede tener muchos registros coincidentes en la Tabla B, y viceversa. Este tipo de relación sólo es posible si se define una tercera tabla (denominada tabla de unión) cuya clave principal (clave principal: uno o más campos (columnas) cuyos valores identifican de manera exclusiva cada registro de una tabla. Una clave principal no puede permitir valores Nulo y debe tener siempre un índice exclusivo.
Una clave principal se utiliza para relacionar una tabla con claves externas de otras tablas.) consta de dos campos : las claves externas (clave externa: uno o más campos de tabla (columnas) que hacen referencia al campo o campos de clave principal de otra tabla. Una clave externa indica cómo están relacionadas las tablas.) de las Tablas A y B. Una relación de varios a varios no es sino dos relaciones de uno a varios con una tercera tabla. Por ejemplo, la tabla Pedidos y la tabla Productos tienen una relación de varios a varios que se define mediante la creación de dos relaciones de uno a varios con la tabla Detalles de pedidos. Un pedido puede incluir muchos productos, y cada producto puede aparecer en muchos pedidos.
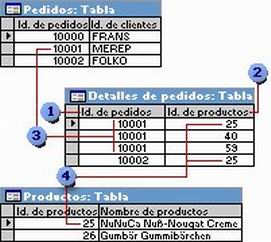
Clave principal de la tabla Pedidos
Clave principal de la tabla Productos
Un pedido puede incluir muchos productos ...
y cada producto puede aparecer en muchos pedidos.
En una relación uno a uno, cada registro de la Tabla A sólo puede tener un registro coincidente en la Tabla B y viceversa. Este tipo de relación no es habitual, debido a que la mayoría de la información relacionada de esta forma estaría en una sola tabla. Puede utilizar la relación uno a uno para dividir una tabla con muchos campos, para aislar parte de una tabla por razones de seguridad o para almacenar información que sólo se aplica a un subconjunto de la tabla principal. Por ejemplo, puede crear una tabla que registre los empleados participantes en un partido de fútbol benéfico. Cada jugador de fútbol de la tabla Jugadores de fútbol tiene un registro coincidente en la tabla Empleados.
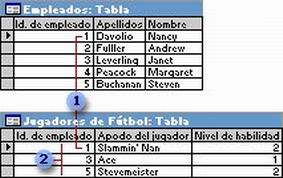
Cada jugador de fútbol tiene un registro coincidente en la tabla Empleados.
Este conjunto de valores es un subconjunto del campo Id. de empleado y la tabla Empleados.
El tipo de relación que crea Microsoft Access depende de cómo están definidos los campos relacionados.
Una relación de uno a varios se crea si sólo uno de los campos relacionados es una qclave principal (clave principal: uno o más campos (columnas) cuyos valores identifican de manera exclusiva cada registro de una tabla. Una clave principal no puede permitir valores Nulo y debe tener siempre un índice exclusivo. Una clave principal se utiliza para relacionar una tabla con claves externas de otras tablas.) o tiene un índice único (índice único: índice que se define al establecer la propiedad Indexado de un campo como Sí (Sin duplicados). Un índice único no permite entradas duplicadas en el campo indizado. Al establecer un campo como clave principal, queda automáticamente definido como exclusivo.).
Se crea una relación uno a uno si ambos campos relacionados son claves principales o tienen índices únicos.
Una relación de varios a varios es, en realidad, dos relaciones de uno a varios con una tercera tabla cuya clave principal consta de dos campos: las claves externas (clave externa: uno o más campos de tabla (columnas) que hacen referencia al campo o campos de clave principal de otra tabla. Una clave externa indica cómo están relacionadas las tablas.) de las otras dos tablas.
También se puede crear una relación entre una tabla y los elementos que contiene. Esto es útil en situaciones en que deba realizar una búsqueda dentro de la misma tabla. Por ejemplo, en la tabla Empleados se puede definir una relación entre los campos Id. de empleado y Jefe, por lo que el campo Jefe puede mostrar datos de empleado que procedan de un Id. de empleado coincidente.
una clave principal (tambian llamada llave primaria) identifica de forma unica cada registro de una tabla en la base de datos, evitando duplicados. para crear rapidamente una clave principal con campos multiples sigue este sencillo procedimiento: desde la vista dise?o de tabla , mantan presionada la tecla ctrl y haz clic sobre cada campo que quieras usar como clave principal. utiliza el comando edicion -> clave principal (o bien, haz clic sobre el boton clave principal de la barra de herramientas dise?o de tabla ). si deseas establecer el modo de apertura predeterminado (compartido o exclusivo) de la base de datos, puedes hacerlo mediante el comando herramientas -> opciones , ficha avanzadas.
- Una tabla nos sirve para guardar y ordenar la informacion de manera mas eficiente y las claves para encontrar los datos mas rapido y las relaciones sirven para enlazar unas tablas con otras.
http://www.duiops.net/manuales/access/access10.htm
dato, campo y registro
- CAMPO, DATO Y REGISTRO
Un campo puede ser, por ejemplo, el nombre de una persona. Los nombres de los campos, no pueden empezar con espacios en blanco y caracteres especiales. No pueden llevar puntos, ni signos de exclamación o corchetes. Si pueden tener espacios en blanco en el medio. La descripción de un campo, permite aclarar información referida a los nombres del campo. El tipo de campo, permite especificar el tipo de información que cargaramos en dicho campo, esta puede ser:
Texto: para introducir cadenas de caracteres hasta un máximo de 255
Memo: para introducir un texto extenso. Hasta 65.535 caracteres
Numérico: para introducir números
Fecha/Hora: para introducir datos en formato fecha u horaMoneda: para introducir datos en formato número y con el signo monetarioAutonumérico: en este tipo de campo, Access numera automáticamente el contenido
Sí/No: campo lógico. Este tipo de campo es sólo si queremos un contenido del tipo Sí/No, Verdadero/Falso, etc.
Objeto OLE: para introducir una foto, gráfico, hoja de cálculo, sonido, etc.
Hipervínculo: podemos definir un enlace a una página Web
Asistente para búsquedas: crea un campo que permite elegir un valor de otra tabla o de una lista de valores mediante un cuadro de lista o un cuadro combinado.
Cada tabla se compone de campos y registros. A pesar de que a primera vista casi la podríamos confundir con una hoja de Excel, existen unas diferencias fundamentales:
en Access, cada columna en una tabla es un campo y cada fila de una tabla representa un único registro que reúne la información de un elemento de la tabla. Cada campo de Access sólo puede tener un tipo de datos: o sólo texto, o sólo números, etc.
Los tipos de datos más utilizados son los números, el texto, la fecha y la moneda pero el Access no se limita a esto: podemos insertar también hipervínculos y además los los objetos OLE, por ejemplo, imágenes, sonidos e incluso los video clips.
- un campo en una tabla de access puede ser por ejemplo npmbre el dato seria el nombre de una persona y la informacion de ellas el registro seria lo que queda guardado los campos, datos y registros pueden ser numericos, alfanumericos, cibergraficos, de fecha etc.
http://www.monografias.com/trabajos5/basede/basede.shtml
BASE DE DATOS
Una base de datos o banco de datos es un conjunto de datos pertenecientes a un mismo contexto y almacenados sistemáticamente para su posterior uso. En este sentido, una biblioteca puede considerarse una base de datos compuesta en su mayoría por documentos y textos impresos en papel e indexados para su consulta. En la actualidad, y debido al desarrollo tecnológico de campos como la informática y la electrónica, la mayoría de las bases de datos están en formato digital (electrónico), que ofrece un amplio rango de soluciones al problema de almacenar datos.
Existen programas denominados sistemas gestores de bases de datos, abreviado SGBD, que permiten almacenar y posteriormente acceder a los datos de forma rápida y estructurada. Las propiedades de estos SGBD, así como su utilización y administración, se estudian dentro del ámbito de la informática.
Las aplicaciones más usuales son para la gestión de empresas e instituciones públicas. También son ampliamente utilizadas en entornos científicos con el objeto de almacenar la información experimental.
Aunque las bases de datos pueden contener muchos tipos de datos, algunos de ellos se encuentran protegidos por las leyes de varios países. Por ejemplo, en España los datos personales se encuentran protegidos por la Ley Orgánica de Protección de Datos de Carácter Personal (LOPD).
- una base de datos es una forma de almacenar datos organizandolos para un mejor entendimiento.
- http://es.wikipedia.org/wiki/Base_de_datos
Suscribirse a:
Entradas (Atom)

